Unicode平面
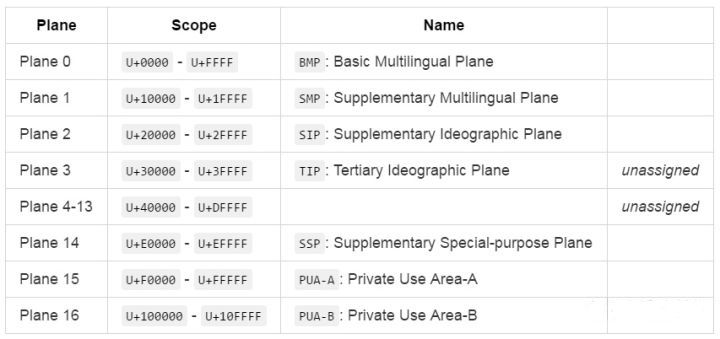
Plane 0, 称作基本平面(Basic Plane), 剩余的称作扩展平面(Supplementary Plane)
| Unicode code points | Range | Encoding Binary value (码点) |
|---|---|---|
| U+000000-U+00007f | 0xxxxxxx | 0xxxxxxx |
| U+000080-U+0007ff | 110yyyxx 10xxxxxx | 00000yyy xxxxxxxx |
| U+000800-U+00ffff | 1110yyyy 10yyyyxx 10xxxxxx | yyyyyyyy xxxxxxxx |
| U+010000-U+10ffff | 11110zzz 10zzyyyy 10yyyyxx 10xxxxxx | 000zzzzz yyyyyyyy xxxxxxxx |
Python中的转义序列
| 转义序列 | 意义 | 示例 | 码点范围 |
|---|---|---|---|
| \ooo(三个八进制数) | ooo码点的字符 | '\141' (a) | U+0 - U+01FF |
| \xhh | hh码点的字符 | '\x61' (a) | U+0 - U+FF |
| \uxxxx | xxxx码点的字符 | '\u4e2d\u6587' (中文) | U+0 - U+FFFF |
| \Uxxxxxxxx | xxxxxxxx码点的字符 | '\U0001f466' (👦) | U+0 - U+FFFFFFFF |
注: \u和\U仅在字符串字面值中可用. o为八进制digit, x和h均为十六进制digit.
注: 对于\ooo, 和Standard C一样, up to three octal digits are accepted.
对于\xhh和\ooo, In a bytes literal, 十六进制和八进制转义序列表示 the byte with the given value. In a string literal, these escapes denote a Unicode character with the given value.
'中'.encode('utf-8')
# b'\xe4\xb8\xad'
# 11100100 10111000 10101101
Java中的转义序列
| 转义序列 | 意义 | 示例 |
|---|---|---|
| \uxxxx | xxxx码点的字符 | "\u4e2d\u6587" (中文) |
| \uxxxx | xxxx码点的字符 | "\ud83d\udc66" (👦) |
注意: Java中没有\Uxxxxxxxx这种形式的转义序列
How many characters can be mapped with Unicode?
The count of all the possible valid combinations in Unicode.
1,111,998: 17 planes × 65,536 characters per plane - 2048 surrogates - 66 noncharacters
Note that UTF-8 and UTF-32 could theoretically encode much more than 17 planes, but the range is restricted based on the limitations of the UTF-16 encoding.
137,994 code points are actually assigned in Unicode 12.1.
utf 8 - How many characters can be mapped with Unicode? - Stack Overflow
编码方式之ASCII、ANSI、Unicode概述 - 蓝海人 - 博客园
十六进制、八进制和二进制的关系
一个十六进制digit对应4个bit, 即半个字节. 一个八进制digit对应3个bit.
UTF-16
在基本平面内, 从U+D800到U+DFFF的码点不对应任何字符.
UTF-16就利用保留下来的0xD800到0xDFFF的码点来映射扩展平面的字符.
U+D800 - U+DBFF, U+DC00 - U+DFFF, 分别有1024个不同的码点.
利用这两段码点结对编码扩展平面的字符, 扩展平面可编码字符数: 1024*1024=1048576.
Unicode 编码及 UTF-32, UTF-16 和 UTF-8 - 知乎
UTF-8

Modified UTF-8
In Modified UTF-8 (MUTF-8), the null character (U+0000) uses the two-byte overlong encoding 11000000 10000000 (hexadecimal C0 80), instead of 00000000 (hexadecimal 00).
BMP的字符, 除了U+0000, 其他的字符Modified UTF-8和UTF-8编码方式一致.
non-BMP的字符, Modified UTF-8用6个字节编码, 而UTF-8用4个字节编码.
UTF8 --> CESU-8 (non-BMP用6个字节编码) --> Modified UTF-8(U+0000用两个字节编码; non-BMP同CESU-8)
Chapter 4. The class File Format
cesu8 - Rust
CESU-8 - Wikipedia
码点和代码单元
码点(Code Point): 是Unicode代码空间中的一个值, 取值从0x0到0x10FFFF, 代表一个字符.
代码单元(Code Unit): 是具体编码形式中的最小单位. 比如UTF-16中一个代码单元为16 bits, UTF-8中一个代码单元为8 bits. 一个码点可能由一个或多个代码单元表示. 在U+10000之前的码点可以由一个UTF-16代码单元表示, U+10000及之后的码点由两个UTF-16代码单元表示.
代码点(Code Point)和代码单元(Code Unit) - zhangzl419 - 博客园
Emoji与Unicode · Zablog
import java.nio.charset.StandardCharsets;
public class Demo {
public static void main(String[] args) {
String str = "你";
printLen(str);
str = "👦";
printLen(str);
str = "你👦";
printLen(str);
//只得到了半个👦
System.out.println(str.charAt(1));
System.out.println(str.substring(str.indexOf("👦"), str.toCharArray().length));
}
public static void printLen(String str) {
System.out.println(str);
System.out.println("string length = " + str.length());
System.out.println("string bytes length (UTF-8) = " + str.getBytes(StandardCharsets.UTF_8).length);
System.out.println("string bytes length (UTF-16BE) = " + str.getBytes(StandardCharsets.UTF_16BE).length);
System.out.println("string char length = " + str.toCharArray().length);
System.out.println("string code points count = " + str.codePoints().count());
System.out.println();
}
}
/*
你
string length = 1
string bytes length (UTF-8) = 3
string bytes length (UTF-16BE) = 2
string char length = 1
string code points count = 1
👦
string length = 2
string bytes length (UTF-8) = 4
string bytes length (UTF-16BE) = 4
string char length = 2
string code points count = 1
你👦
string length = 3
string bytes length (UTF-8) = 7
string bytes length (UTF-16BE) = 6
string char length = 3
string code points count = 2
?
👦
代码片段
//遍历码点
String str = "👦abc";
str.codePoints().forEach(c -> new String(Character.toChars(c)));
//取得第一个码点的字符
String firstSymbol = new String(Character.toChars(str.codePointAt(0)));
System.out.println(firstSymbol);
获取字符的码点及其编码(UTF,GB18030)
str = '👦'
print('Code Point', format(ord(str), 'x'))
encodingList = ["UTF-8", "UTF-16-LE",
"UTF-16-BE", "UTF-32-LE", "UTF-32-BE", "GB18030"]
for encoding in encodingList:
byteHexStr = ''
for byte in bytearray(str, encoding):
byteHexStr += format(byte, 'x').zfill(2)
print(encoding, byteHexStr)
# 输出
"""
Code Point 1f466
UTF-8 f09f91a6
UTF-16-LE 3dd866dc
UTF-16-BE d83ddc66
UTF-32-LE 66f40100
UTF-32-BE 0001f466
GB18030 9439d336
"""
import java.nio.ByteBuffer;
import java.nio.IntBuffer;
import java.util.Arrays;
import java.util.LinkedHashMap;
import java.util.Map;
class Demo {
private static final char[] HEX_ARRAY = "0123456789abcdef".toCharArray();
public static String bytesToHex(byte[] bytes) {
char[] hexChars = new char[bytes.length * 2];
for (int j = 0; j < bytes.length; j++) {
int v = bytes[j] & 0xFF;
hexChars[j * 2] = HEX_ARRAY[v >>> 4];
hexChars[j * 2 + 1] = HEX_ARRAY[v & 0x0F];
}
return new String(hexChars);
}
public static void main(String args[]) throws Exception {
String str = "👦";
int[] codePointArr = str.codePoints().toArray();
System.out.println("Code Point " + Integer.toHexString(codePointArr[0]));
String[] encodingArr = { "UTF-8", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE", "GB18030" };
Map<String, String> encodingMap = new LinkedHashMap<>();
for (String encoding : encodingArr) {
byte[] arr = str.getBytes(encoding);
encodingMap.put(encoding, bytesToHex(arr));
}
encodingMap.forEach((k, v) -> System.out.println(k + " " + v));
}
}
字节序和BOM
- 计算机硬件有两种储存数据的方式: 大端字节序(big endian)和小端字节序(little endian).
例如, 数值0x2211使用两个字节储存: 高位字节是0x22, 低位字节是0x11.
大端字节序: 高位字节在前, 低位字节在后, 即0x2211.
小端字节序: 低位字节在前, 高位字节在后, 即0x1122. - BOM=Byte Order Mark, 即"字节顺序标识".
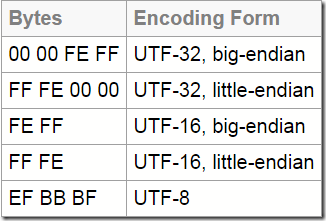
UTF-16, JVM中缺省是大端法,Windows平台下缺省为小端法.
理解字节序 - 阮一峰的网络日志
字符集与编码(七)——BOM – 肖国栋的i自留地
MySQL排序规则
| 排序规则 | Unicode collation algorithm |
|---|---|
| utf8mb4_unicode_ci | 基于UCA 4.0.0 |
| utf8mb4_unicode_520_ci | 基于UCA 5.2.0 |
| utf8mb4_0900_ai_ci | 基于UCA 9.0.0, since MySQL 8.0 |
The Unicode collation algorithm (UCA) is an algorithm defined in Unicode Technical Report #10, which defines a customizable method to compare two strings.